
Definition
Core
DFD is an approach, backed by principles, which focuses on the importance of:
- Viewing almost every possible context in the DevOps process i.e. input, output or any process, as data.
- To store all the data in relevant data store
- Using the data to do the DevOps activities
Below given are few terminologies which might be helpful:
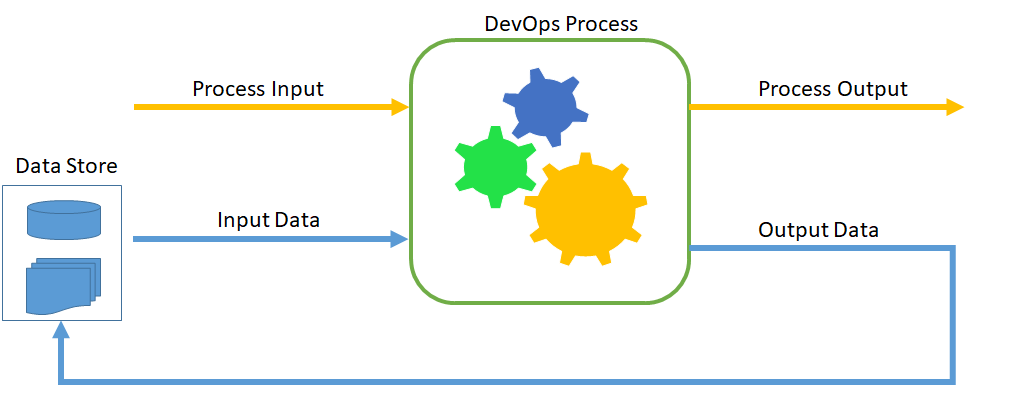
Process input
The input required to trigger a DevOps process, irrespective of DFD.
Input data
The data we use either to support the process input or to support the DevOps process is considered as input data.
Process output
The output of the DevOps process is considered as process output.
Output data
The metadata about the process output or the DevOps process can be considered as Output data.
Visual Representation
Example
Let's understand the above diagram with a simple example:
Assume that the process we are talking about is build process of a given Microservice, which is being triggered by a developer. In that case:
Process Input
Being a generous DevOps implementer, it would be called being tough to handle pipeline if you ask the developer to give the Git Repo URL of the Microservice, s/he is trying to build. It would be just simpler if you give him a drop down which lists all the names of the Microservices in alphabetical order and s/he just needs to select the name of the Microservice intended for build. It is assumed that we are a maturity level, where we don’t create a new pipeline for every new Microservice, rather we reuse one but parameterized pipeline. So, in this case the Process Input is the name of the Microservice.
Input Data
Now there are two things which goes as input data. Let's see them:
The list of Microservice names: Did it come to your mind, how the list of the Microservices being populated? If so, then you are very close to understand DFD. The answer is, as everything should be treated as data as far as possible, we need to have a data store with a dataset which is mapping of Microservice name to its Git repo URL. From this mapping we can fetch the list of the names of Microservices. This is one input data, and this is used even before the developer chooses to take any action. Here input data is supporting the process input.
The Microservice name to Git URL mapping: Once the developer selects the Order Service to be built, we can again use the same mapping data to find out the relevant Git repo which is to be built as per the request of the developer. This becomes second input data and is used when a process actually got started i.e. data used in run time of the build process. Here input data is supporting the DevOps process.
DevOps Process
There is absolutely no need to explain the process of the build for a DevOps expert like you here. Yet for the sake of the documentation, DevOps process here indicates the build + unit test execution + quality scan + deployable creation (here a docker image) + deployable storage (a docker repository).
Process Output
In our case, let's assume that the process output is the docker image which has been pushed to the docker registry. No rocket science here.
Output Data
Now we can have many output data which can be recorded here. Here is the list, and you can add to it:
- Build trigger time
- Build duration
- Built by
- Git URL
- Git branch
- Git commit id
- Created docker tag number
Now we can use this output data in future for various purpose. If at this point you are thinking that this is Data Driven DevOps, then the answer is - it depends on how you use the data. We will discuss about Data Driven DevOps to Data First DevOps comparison later.