
Implementing
We have looked at the requirement and mapped the data associated with every element in the Designing DFD page. Now we have the data. Next step is how to integrate it with the DevOps pipelines. Though I would keep it open for you to decide what would be your data source, yet the pipeline (pseudo code), using Jenkins would look something like this:
Build Pipeline
Screenshot
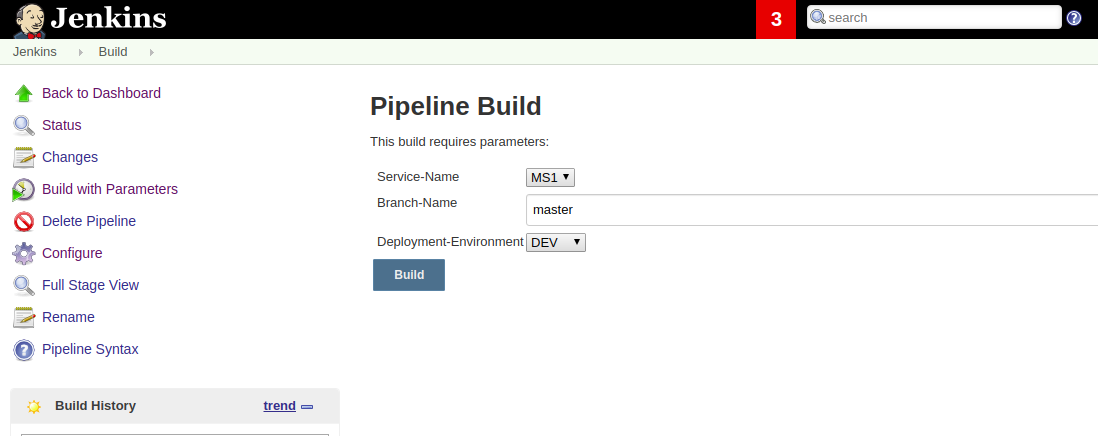
Pseudo source code
Step 1: defined a function to return list of services from database table
def getMSList(){
// Write the code here to pull the list of microservice from your
// selected data source.
}
Step 2: Save above list returned from above function
def MSList = getMSList()
Step 3: Set the above List into ExtendedChoiceParameterDefinition
microserviceChoiceObject.setValue(MSList)
Step 4: Use the above ExtendedChoice Object into pipeline parameters
properties([
parameters([
microserviceChoiceObject
])
])
Environment list can also be fetched and prepopulate into job parameters using the same above approach
Step 5: Write Checkout, Build, static code analysis if any and then docker build and publish steps
pipleine{
stages{
stage('checkout'){
code checkout from SCM
}
stage('Build'){}
stage('Code Analysis'){}
stage('docker build and publish'){}
stage('Build Logging'){
// Log the build related details in your data source.
}
}
}
Deployment Pipeline
Screenshot
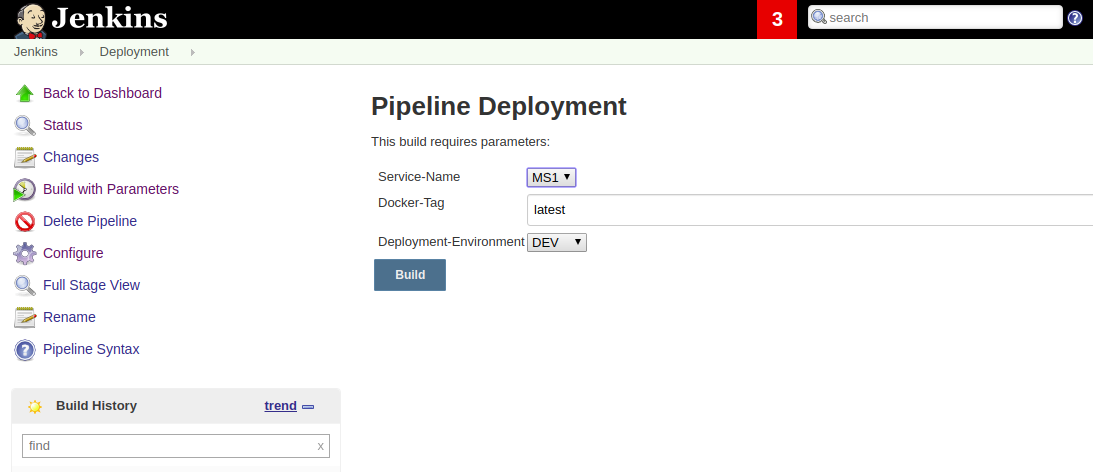
Pseudo source code
Fetch the Services and Deployment-Environment values from data source into the drop-down same like above build steps(1-4)
Pipeline Step:
pipleine{
stages{
stage('Deployment'){
// Write code to pull the Cluster_Id and Credential_id from data source based on user param
// Script to deploy into above K8S cluster_id
}
stage('Deployment Logging'){
// Log the deployment related details in your data source.
}
}
}
Environment Configuration
Screenshot
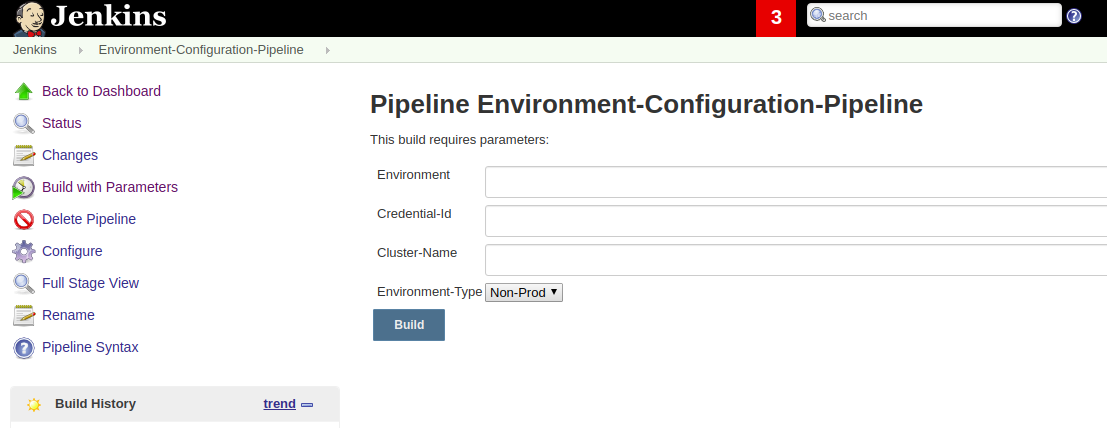
Pseudo Source code:
pipeline{
stages{
stage('Environment Configuration'){
// Write the code to insert environment details into env data source
}
}
}
Approach
Look carefully on your requirements, select a data source which is feasible to use economically, legally and technically.
The glitch
Take care of "Data Cohesion" principle.